
Table of Contents
Struggling with Video Captioning? Meet Your New Solution
Have you ever needed to extract meaningful captions from video content but found the process tedious and time-consuming? Whether you’re a content creator, researcher, developer, or accessibility advocate, ViT Captioner is the powerful open-source tool you’ve been waiting for.
What is ViT Captioner?
ViT Captioner is a Python package that leverages the powerful ViT-GPT2 model to automatically extract keyframes from videos and generate natural language captions. This tool bridges the gap between computer vision and natural language processing to provide accurate, context-aware descriptions of video content.
Key Features That Set ViT Captioner Apart
- Intelligent Keyframe Extraction: Uses Katna to identify the most meaningful frames in your videos, with a fallback to uniform sampling
- High-Quality Captioning: Generates descriptive captions using the state-of-the-art ViT-GPT2 model
- Flexible Output Formats: Creates SRT subtitle files, JSON data, and captioned images
- Timeline Visualization: Visualize keyframes and their timestamps on an interactive timeline
- Performance Optimized: Smart resource management, thread-safe processing, and progress indicators
- Developer-Friendly API: Simple Python interface for integration into your own applications
- Command-Line Interface: Easy-to-use commands for quick batch processing
Real-World Applications
- Content Creators: Generate subtitle files for your videos to improve accessibility and SEO
- Researchers: Automatically analyze video datasets with accurate frame descriptions
- Developers: Integrate video understanding capabilities into your applications
- Educators: Make educational videos more accessible with accurate captions
- Media Archivists: Index and search video collections based on visual content
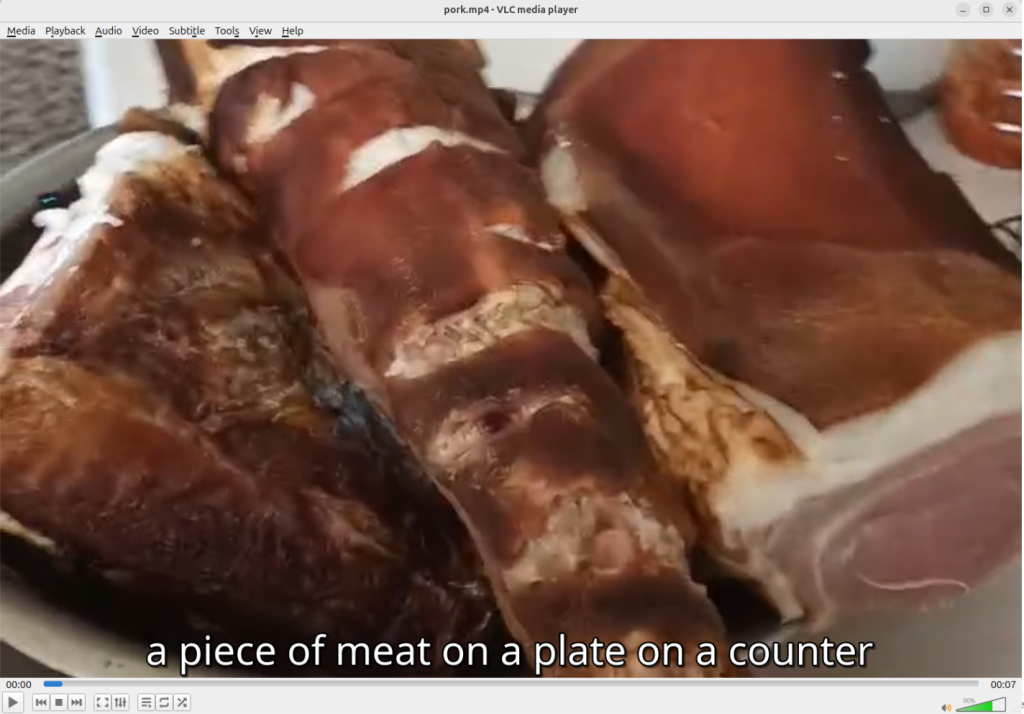
See It In Action
ViT Captioner produces both SRT subtitle files and structured JSON data:
1
00:00:00,000 --> 00:00:00,922
a piece of meat on a plate on a counter
2
00:00:00,922 --> 00:00:01,844
a piece of meat is being cooked in a pan
It also creates captioned images that combine visual content with descriptive text, making it easy to understand the context of each keyframe.
Getting Started in Minutes
Installation is straightforward with pip:
pip install vit-captioner
Generate captions for an entire video with a single command:
vit-captioner caption-video -V /path/to/video.mp4 -N 10 -v
Or use the Python API for more advanced integration:
from vit_captioner.captioning.video import VideoToCaption
converter = VideoToCaption("/path/to/video.mp4", num_frames=10, verbose=True)
converter.convert()
Built On Solid Foundations
ViT Captioner leverages the power of several cutting-edge open-source projects:
- nlpconnect/vit-gpt2-image-captioning for state-of-the-art image captioning
- Katna for intelligent keyframe extraction
- PyTorch and the Hugging Face Transformers library for efficient deep learning
Try ViT Captioner Today
Ready to transform how you work with video content? ViT Captioner is available on GitHub and PyPI:
Give it a star if you find it useful, and contributions are always welcome!
Have you tried ViT Captioner? Share your experience in the comments below or reach out with any questions about implementing it in your workflow.